

A few months ago JPCERT/CC released a “new” techinque they’ve encountered, where Bad Guys generated a DOC/PDF polyglot to bypass VBA detection. I’ve put “new” in quotes just because veterans definitely remember exactly the same technique being used as early as 2014-2015. Well, maybe novelty here is that the Baddies figured out how good of a polyglot MHT format really is, not sure.
Anyway, after their publication, all of the analysis out there followed the usual flow of “I’ll just shove this thing into CyberChef, then oletools and write several pages about it”, so I’ve decided it makes sense to dive just a little bit deeper into this technique.
Turned out, besides obvious polyglot capabilities, there’s a little bit more obscure functionality to abuse.
Also, I’d like to give a big shout-out to a buddy of mine for helping me with reversing huge Office’s DLLs and figuring this out overall.
Now, let’s get down to business.
TL;DR
It’s possible to tamper with VbaSuppData contents to achieve auto-execution of arbitrarily named VBA macros. On top of that, there’s also a few opportunities for additional detection bypass due to mismatch in zlib decompression implementation, multipart data extraction and amazing polyglot capabilities of MHTML format. You can find the tool to play around with it here.
Word document in MHTML
I’m not going to do MHTML for dummies here - you are more than capable to google the details. But just for completeness sake and to underline the part that’s relevant for this research, here’s what an average Word document with a macros inside looks like in MHTML:
MIME-Version: 1.0
Content-Type: multipart/related; boundary="----=_NextPart_01DA0113.4B769540"
------=_NextPart_01DA0113.4B769540
Content-Location: file:///C:/8D882234/simple-document.htm
Content-Transfer-Encoding: quoted-printable
Content-Type: text/html; charset="windows-1252"
<html xmlns:v=3D"urn:schemas-microsoft-com:vml"
xmlns:o=3D"urn:schemas-microsoft-com:office:office"
xmlns:w=3D"urn:schemas-microsoft-com:office:word"
xmlns:m=3D"http://schemas.microsoft.com/office/2004/12/omml"
xmlns=3D"http://www.w3.org/TR/REC-html40">
<head>
<meta http-equiv=3DContent-Type content=3D"text/html; charset=3Dwindows-125=
2">
<meta name=3DProgId content=3DWord.Document>
<meta name=3DGenerator content=3D"Microsoft Word 15">
<meta name=3DOriginator content=3D"Microsoft Word 15">
<link rel=3DFile-List href=3D"simple-document_files/filelist.xml">
<link rel=3DEdit-Time-Data href=3D"simple-document_files/editdata.mso">
<!--[if gte mso 9]><xml>
<o:DocumentProperties>
<o:Author>user</o:Author>
..........snip..........
</head>
<body lang=3DEN-US style=3D'tab-interval:.5in;word-wrap:break-word'>
<div class=3DWordSection1>
<p class=3DMsoNormal><o:p> </o:p></p>
</div>
</body>
</html>
------=_NextPart_01DA0113.4B769540
Content-Location: file:///C:/8D882234/simple-document_files/themedata.thmx
Content-Transfer-Encoding: base64
Content-Type: application/vnd.ms-officetheme
UEsDBBQABgAIAAAAIQDp3g+//wAAABwCAAATAAAAW0NvbnRlbnRfVHlwZXNdLnhtbKyRy07DMBBF
90j8g+UtSpyyQAgl6YLHjseifMDImSQWydiyp1X790zSVEKoIBZsLNkz954743K9Hwe1w5icp0qv
8kIrJOsbR12l3zdP2a1WiYEaGDxhpQ+Y9Lq+vCg3h4BJiZpSpXvmcGdMsj2OkHIfkKTS+jgCyzV2
JoD9gA7NdVHcGOuJkTjjyUPX5QO2sB1YPe7l+Zgk4pC0uj82TqxKQwiDs8CS1Oyo+UbJFkIuyrkn
9S6kK4mhzVnCVPkZsOheZTXRNajeIPILjBLDsAyJX89nIBkt5r87nons29ZZbLzdjrKOfDZezE7B
/xRg9T/oE9PMf1t/AgAA//8DAFBLAwQUAAYACAAAACEApdan58AAAAA2AQAACwAAAF9yZWxzLy5y
ZWxzhI/PasMwDIfvhb2D0X1R0sMYJXYvpZBDL6N9AOEof2giG9sb69tPxwYKuwiEpO/3qT3+rov5
4ZTnIBaaqgbD4kM/y2jhdj2/f4LJhaSnJQhbeHCGo3vbtV+8UNGjPM0xG6VItjCVEg+I2U+8Uq5C
..........snip..........
------=_NextPart_01DA0113.4B769540
Content-Location: file:///C:/8D882234/simple-document_files/colorschememapping.xml
Content-Transfer-Encoding: quoted-printable
Content-Type: text/xml
<?xml version=3D"1.0" encoding=3D"UTF-8" standalone=3D"yes"?>
<a:clrMap xmlns:a=3D"http://schemas.openxmlformats.org/drawingml/2006/main"=
bg1=3D"lt1" tx1=3D"dk1" bg2=3D"lt2" tx2=3D"dk2" accent1=3D"accent1" accent=
2=3D"accent2" accent3=3D"accent3" accent4=3D"accent4" accent5=3D"accent5" a=
ccent6=3D"accent6" hlink=3D"hlink" folHlink=3D"folHlink"/>
------=_NextPart_01DA0113.4B769540
Content-Location: file:///C:/8D882234/simple-document_files/editdata.mso
Content-Transfer-Encoding: base64
Content-Type: application/x-mso
QWN0aXZlTWltZQAAAfAEAAAA/////wAAB/AIDgAABAAAAAQAAAAAAAAAAAAAAAAsAAB4nO1afWxb
VxU/79lJbTfp3JBtbVfWV6fb2izOnj/iJF0z4s+kXVJnTZbsw6x1nJfGnWNntrNmlG3uWokBQwMN
gZjYgG4aEmJVN8Qk0JBK/wEhNIZAgo2JMRiI/xhIfAhpM7/z3n2289W4KUhs2nn95V6f9+695557
Pu59r6/+bPPvvvHCtrdoCd1CFnqvbKfGGp4koJOTSBa/3yuXyya7/CG9r+hdYINYQyvKBoDX3AZs
BOyAA2gSzzSj3ARcYZgAbQZagI8AreKZD+n9Q4coh6tICkUpizJPDywNBRelq2AxZl+ONZ51vv7a
..........snip..........
------=_NextPart_01DA0113.4B769540
Content-Location: file:///C:/8D882234/simple-document_files/filelist.xml
Content-Transfer-Encoding: quoted-printable
Content-Type: text/xml; charset="utf-8"
<xml xmlns:o=3D"urn:schemas-microsoft-com:office:office">
<o:MainFile HRef=3D"../simple-document.htm"/>
<o:File HRef=3D"themedata.thmx"/>
<o:File HRef=3D"colorschememapping.xml"/>
<o:File HRef=3D"editdata.mso"/>
<o:File HRef=3D"filelist.xml"/>
</xml>
------=_NextPart_01DA0113.4B769540--
The document layout is translated to HTML and stored in the first part, then there’s additional metadata like themes, document file list and so on, but what’s important here is second to last part with location file:///C:/8D882234/simple-document_files/editdata.mso - that’s the VBA project, translated into MS-CFB, compressed into ActiveMime container and base64-encoded.
Original payload
Reproducing original payload is remarkably trivial:
- Just save the document as .mht using Word’s own functionality
- Prepend a pdf magic bytes to it (and maybe some more junk bytes)
- Change the extension to .doc so it’s forced to be opened by Word, not IE
Why not prepend the whole PDF document? Well, some bytes like 0x0A actually breaks the parsing both for analytical tools and for MS Office itself, so you have to be a little bit careful with it.
But really, there’s nothing interesting here, except the fact that Word’s MHTML parser allows to prepend almost any junk to the actual content, but I’ll get back to it later. As for its bypass capabilities, it’s actually kinda meh: it does fool some of the antiviruses into thinking that it’s a PDF and not running appropriate tooling, but as you can see on VirusTotal, it’s not that good anymore, especially after multiple AVs updated their signatures when the initial publication hit the net:
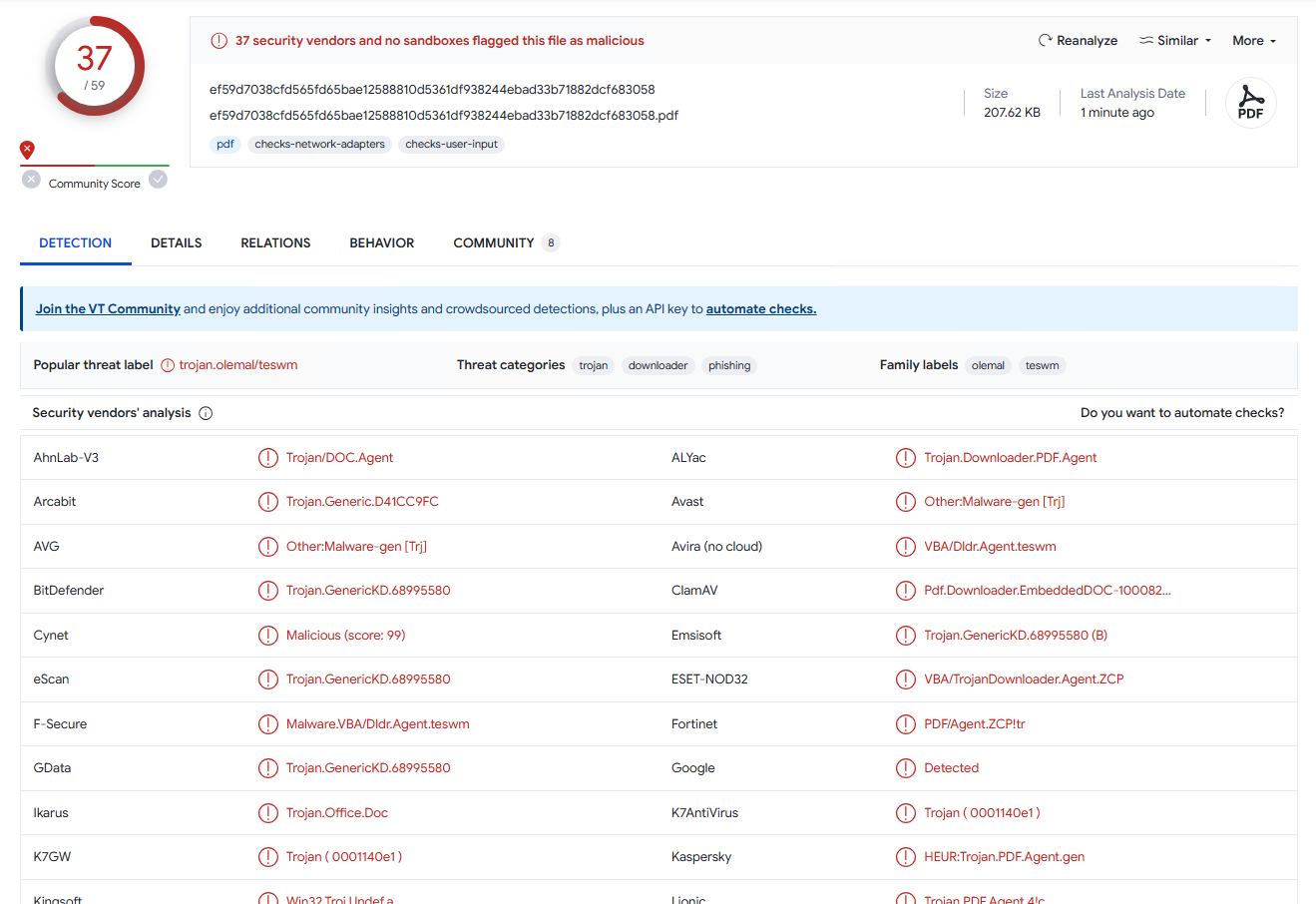
More over, if you just run your trusty oletools, it’s not bothered by the preneded junk at all:
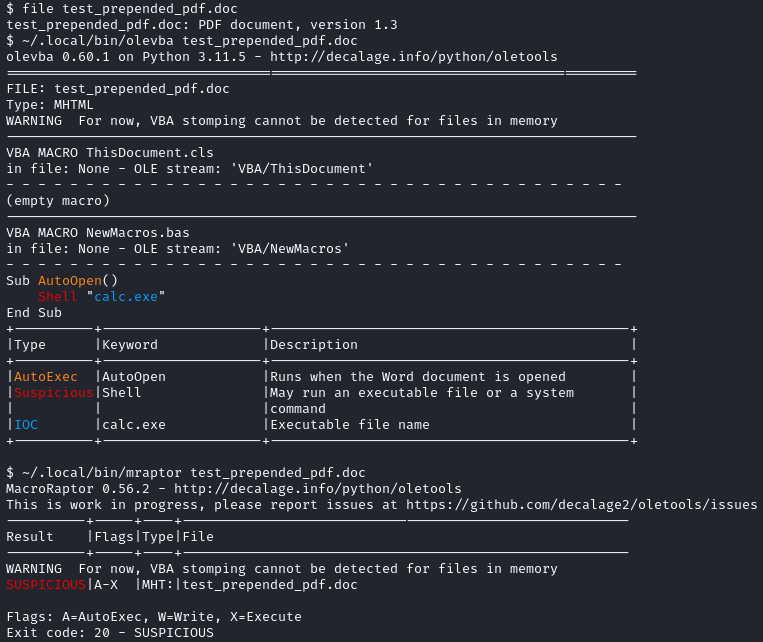
Oletools was also updated to accomodate this polyglot. So, probably before the publication, the detection rates were quite good indeed.
Elusive ActiveMime format
While MS-CFB is very well documented and there are multiple libraries and tools to work with it, the ActiveMime format has no official documentation at all. In fact, the only thing I could find is this repo: a pretty good effort of reverse engineering the format and the parsing tool as well.
Here’s how an average ActiveMime container looks like:
0000:0000 | 41 63 74 69 76 65 4D 69 6D 65 00 00 01 F0 04 00 | ActiveMime...ð..
0000:0010 | 00 00 FF FF FF FF 00 00 07 F0 AC 0D 00 00 04 00 | ..ÿÿÿÿ...ð¬.....
0000:0020 | 00 00 04 00 00 00 00 00 00 00 00 00 00 00 00 2A | ...............*
0000:0030 | 00 00 78 9C ED 5A 7D 6C 5B D5 15 3F EF D9 49 6D | ..x.íZ}l[Õ.?ïÙIm
0000:0040 | D7 69 DD 90 96 B6 94 E6 C5 E9 47 1A 92 F0 9E ED | ×iÝ..¶.æÅéG..ð.í
0000:0050 | 24 4E 69 BA D8 CF 4E D2 92 34 21 09 0D 0C 43 E3 | $NiºØÏNÒ.4!...Cã
0000:0060 | 24 2F A9 5B 3B 0E B6 43 03 A5 D4 A5 95 C6 80 4D | $/©[;.¶C.¥Ô¥.Æ.M
0000:0070 | 0C F6 05 93 40 63 88 69 D5 CA A0 D3 40 9B 8A D4 | .ö..@c.iÕÊ Ó@..Ô
..........snip..........
Let’s parse it real quick, based on the tool I’ve mentioned before:
41 63 74 69 76 65 4D 69 6D 65 00 00- magic bytes01 F0- unknown04 00 00 00- field sizeFF FF FF FF- unknown00 00 07 F0- unknownAC 0D 00 00- compressed size of the container04 00 00 00- field size04 00 00 00- field size00 00 00 00- unknown00 00 00 00- block contains some unencoded VB Project Strings00 2A 00 00- size of uncompressed container78 9C ED 5A ...- zlib-compressed MS-CFB container
There is already quite a bit to play with, because some tools just skip to the compressed data part, relying on the fact that the metadata is always the same size, which is not true. But that’s not too interesting and oletools properly covers this part.
After a little bit of fuzzing and experimentation with different types of macros, I’ve noticed that the length of compressed MS-CFB doesn’t always match with the remaining data till the end of file. There’s always some kind of delimiting footer junk, but sometimes the difference is very significant. Long story short, it turned out that if the document macros contains argumentless procedures, then after declared compressed size bytes there is a whole sector of non-compressed data describing it. Something like this:
0000:0E40 | 09 04 00 00 FF 01 01 00 00 00 56 00 00 00 00 00 | ....ÿ.....V.....
0000:0E50 | FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | ÿÿ..............
0000:0E60 | 00 00 10 FF FF 01 00 02 00 1A 00 50 00 72 00 6F | ...ÿÿ......P.r.o
0000:0E70 | 00 6A 00 65 00 63 00 74 00 2E 00 4E 00 65 00 77 | .j.e.c.t...N.e.w
0000:0E80 | 00 4D 00 61 00 63 00 72 00 6F 00 73 00 2E 00 41 | .M.a.c.r.o.s...A
0000:0E90 | 00 75 00 74 00 6F 00 4F 00 70 00 65 00 6E 00 01 | .u.t.o.O.p.e.n..
0000:0EA0 | 00 11 01 00 00 00 1A 00 50 00 52 00 4F 00 4A 00 | ........P.R.O.J.
0000:0EB0 | 45 00 43 00 54 00 2E 00 4E 00 45 00 57 00 4D 00 | E.C.T...N.E.W.M.
0000:0EC0 | 41 00 43 00 52 00 4F 00 53 00 2E 00 41 00 55 00 | A.C.R.O.S...A.U.
0000:0ED0 | 54 00 4F 00 4F 00 50 00 45 00 4E 00 00 00 40 00 | T.O.O.P.E.N...@.
0000:0EE0 | 00 0B F0 04 00 00 00 12 34 56 78 | ..ð.....4Vx
Just for ease of communication I’ve labeled this chunk “the magic tail”.
The Magic Tail
Playing around with different storage formats for macro-enabled documents, I found out that at least part of this structure is actually a serialized VbaSuppData class.
As for all the other bytes, I’m not going to describe all the attempts to reverse engineer mso.dll and other relevant libraries. Microsoft doesn’t provide symbols for them and blindly poking in several 20-30mb DLLs isn’t fun. So most of the assumptions are mostly based on countless test documents and weeks of fuzzing. Reading MS-OVBA and MS-PROPSTORE was also helpful as this magic tail looks a little bit similar in its structure.
So, let’s parse this example:
09 04 00 00- unknown, probably ID of the whole structrue and the segment countFF- delimiter01- unknown, probably ID of the whole structure or the size of the next value01- size of the structure that follows (array of procedures’ metadata)00 00 00 56 00 00 00 00 00- ‘mcds’ property of VbaSuppData structure, where 56 is ‘cmd’ param and a byte right after (which is ‘00’ here) is ‘bEncrypt’ paramFF FF- delimiter00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 10- unknown, always sameFF FF- delimiter01 00- size of the structure that follows (array of procedures’ names)02 00- unknown1A 00- size of the procedure name50 00 72 00 6F 00 6A 00 65 00 63 00 74 00 2E 00 4E 00 65 00 77 00 4D 00 61 00 63 00 72 00 6F 00 73 00 2E 00 41 00 75 00 74 00 6F 00 4F 00 70 00 65 00 6E 00- ‘name’ param of VbaSuppData, full procedure name (including project and module, delimited by a dot) in UTF-1601 00 11- unknown01 00- size of the structure that follows (array of procedures’ links)00 00- unknown1A 00- size of the procedure link50 00 52 00 4F 00 4A 00 45 00 43 00 54 00 2E 00 4E 00 45 00 57 00 4D 00 41 00 43 00 52 00 4F 00 53 00 2E 00 41 00 55 00 54 00 4F 00 4F 00 50 00 45 00 4E 00- ‘macroName’ param of VbaSuppData, full procedure link in uppercase (including project and module, delimited by a dot), in UTF-1600 00 40 00 00 0B F0 04 00 00 00 12 34 56 78- unknown, probably just static footer
The structure of this magic tail for a macros with more argumentless procedures follows the same principle: there are values for each procedure metadata, delimited by FF FF, values for each procedure name and link as well - I don’t want to bloat this post with too many examples, you are free to check out the code, it should be quite self-explanatory. I still don’t understand what some of the values do and this is just an educated guess and I might be far off, but this is what ended up making sense for me.
At some point I thought that this is just the serialized VbaSuppData structure, but it looks like that there’s a bit more to it, because I couldn’t find any correlation between most of the bytes and values of VbaSuppData in raw XML. Also, there are some parts that I ommited for brevity, like help menu information, but they didn’t provide much more attack surface than there already is.
Now, what’s a bit weird here is that there are two arrays that just store the name of the procedure - one in original case and the other in uppercase. I have two guesses about that:
-
This could be the same as mentioned in MS-OVBA: long time ago, Office didn’t fully support unicode and they stored procedure names in the structure that I called “array of procedures’ names” here. Later, they added unicode support, but they follow strict backwards compatibility rules and couldn’t change what’s already there and just introduced an additional field with unicode names - I called it “array of procedures’ links here.
-
Both structures are used for optimization as it’d be really slow to extract all the macros from CFB to just show the names in a list, for example. So the array of names is used for displaying a list of procedures, when you click on “View Macros” button and the array of links is used to process the event-based procedures faster.
These two don’t really contradict each other, so both could be true or some partial combination. Again, just to have some way of communicating it, I’ve called one ‘procedure name’ and the other one ‘procedure link’.
The reason for this weird naming, especially since these values have their proper names defined in VbaSuppData, is that they aren’t just names - you’ll see in the next section.
Security implications
Procedure name spoofing
While names seem to be purely cosmetic, the links are actually overriding the VBA project parameters that are stored in CFB. So, by changing the link name to something else will actually change its name during VBA interpretation.
This leads to something quite interesting: you can change the link name to some auto-executing procedure like AutoOpen() and it will indeed be executed on document open event, despite the actual VBA project not having AutoOpen() procedure declared at all.
That means, that even if your macros gets properly extracted from the document, for all the AVs and analytical tools there is no auto-executing (and thus suspicious) code at all. Which obviously leads to complete significant decrease in detection rates, at least at the time of writing.
There’s a small caveat, though: the length of the procedure name must not change. For example, if you spoof AutoOpen() procedure which name is 8 characters long, your actual procedure should also be 8 characters long. I’ve tried tampering the bytes that define the length of the name, but with no success. My best guess is that it reads the length of the name from the magic tail and uses it to parse the actual macros data stored in CFB, so the values must match. If you do the same trick in other, non-binary formats (i.e. XML), it does work with any length, but it looks like it changes something in the CFB to make it work and I didn’t bother to find out what exactly, becuase it doesn’t really affect the results.
Also, you can tamper with the order of the procedures in the array: if you have several procedures in the magic tail, you can swap around the IDs and make Office call one procedure instead of another, because it addresses them by name, which will bypass naive heuristics that could be implemented to detect name spoofing.
Polyglot shenanigans
Just to expand the polyglot tricks of the initial payload a little bit, there’s another way to fool olevba. If you take a look at olevba’s parser code, you’ll notice it relies on a lot of arbitrary string matching. It wasn’t that good before, but the fix made to cover the initial polyglot payload made it even worse.
So, let’s take this simple macro-enabled document and parse it with olevba:
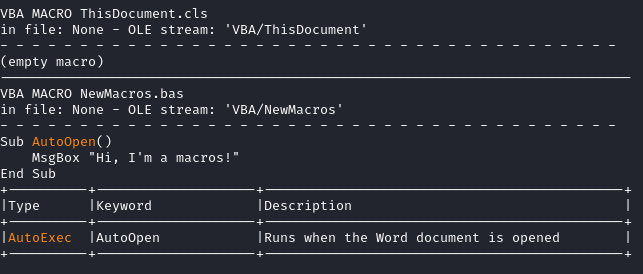
Now, if I prepend a random string to the document, but also make sure to add ‘MIME’ somewhere in there, like so:
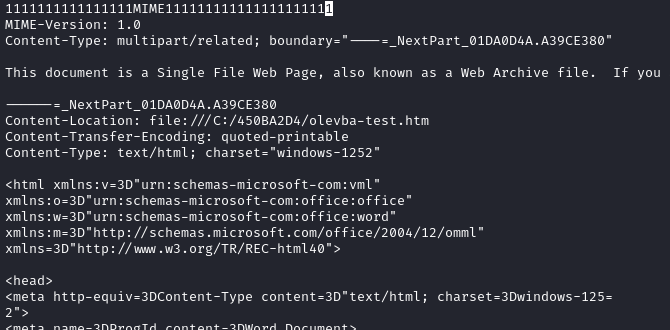
Then olevba can’t even find the macro or parse the document properly at all:
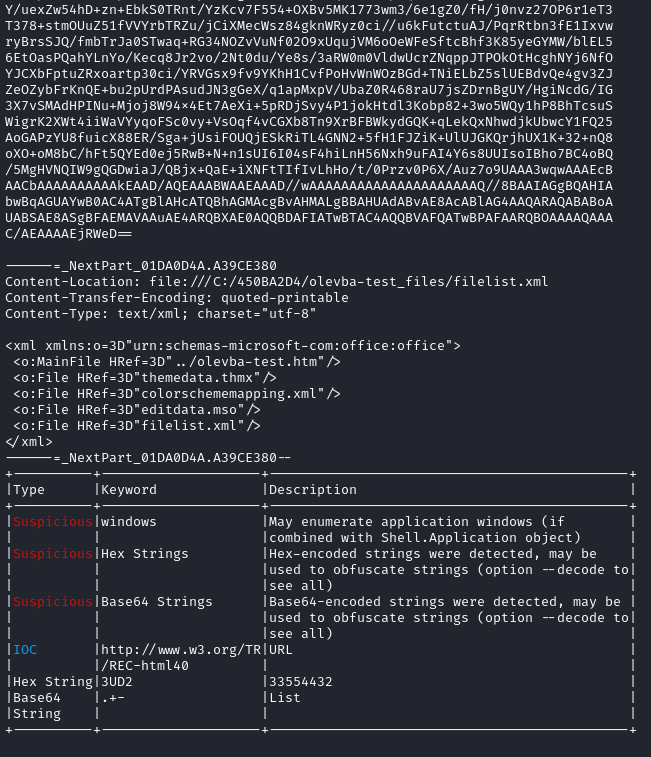
Breaking zlib stream
While fuzzing the values of this magic tail, I’ve stumbled upon some random byte positions that led to olevba unable to decode the CFB, while Office still correctly opening it, leading to quite good detection bypass as some AVs just couldn’t decompress the data at all.
If you take a look at MS-OVBA, you can see that there are a lot of values that are reserved and/or ignored on read. Then, looking at how oletools and others parse ActiveMime, they all assume that zlib-compressed stream continues till the end of file, which I already demonstrated is not the case. So, while Office ignores some bytes, olevba does not and it’s quite easy to make zlib error out with an unexpected byte in compressed stream.
Also, probably due to slightly different implementation, tampering the actual zlib-stream is also a viable technique - MS Office suppresses some of the errors in the stream and decodes the macros correctly.
This technique isn’t that easy to fully automate as it’s somewhat dependent on specific zlib-stream contents and requires semi-manual fuzzing for each payload.
Bypass rate
Now, with the technique actually properly understood, let’s see if it’s any good at evading detection.
I’ll start with the most basic shellcode runner with the usual VirtualAlloc(), RtlMoveMemory() and CreateThread(). The only evasion technique in there will be 1-byte XOR encryption of the payload. This is going to be my benchmark (VirusTotal):
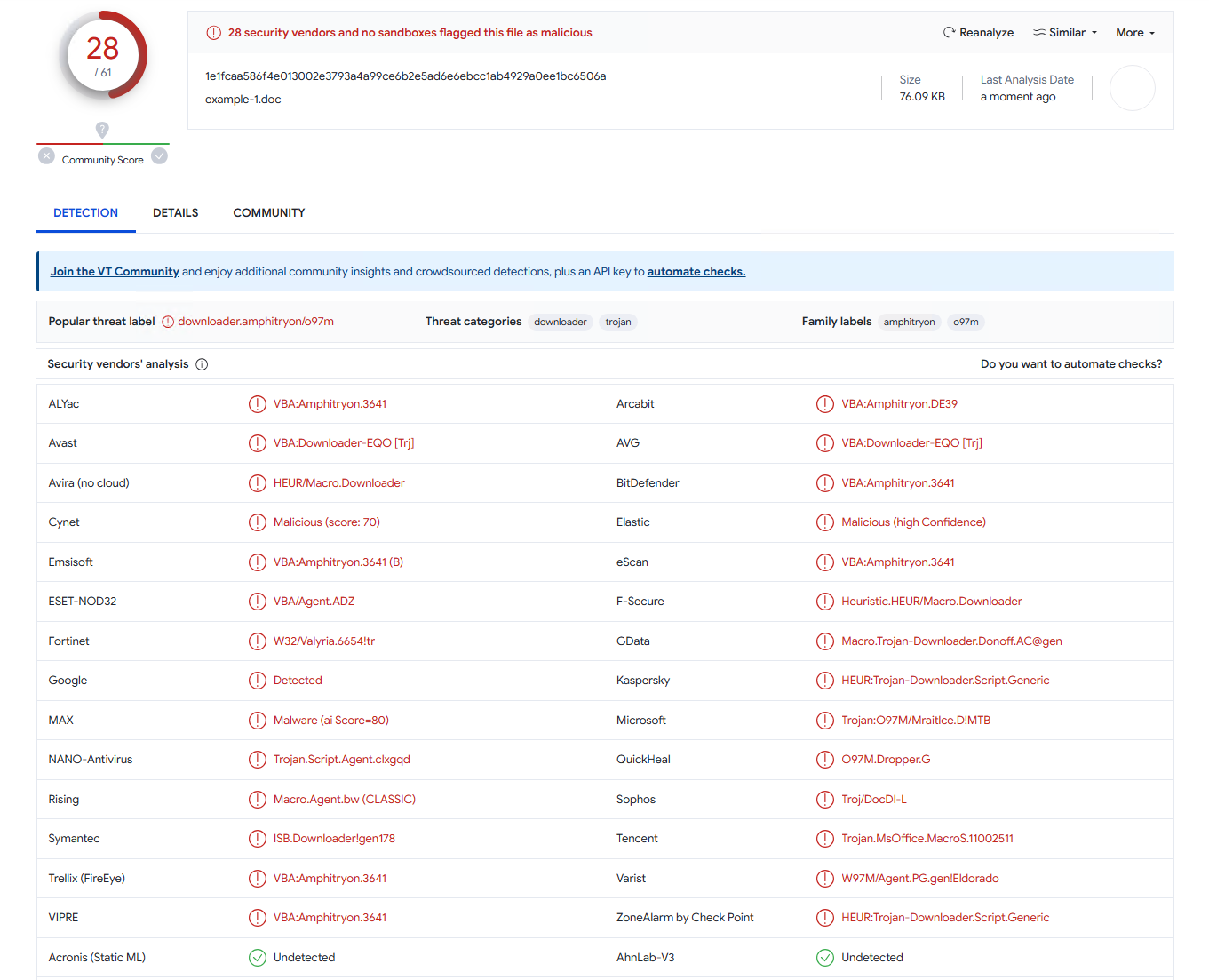
Converting it to MHTML and applying macro name spoofing for AutoOpen(), it get significantly better (VirusTotal):
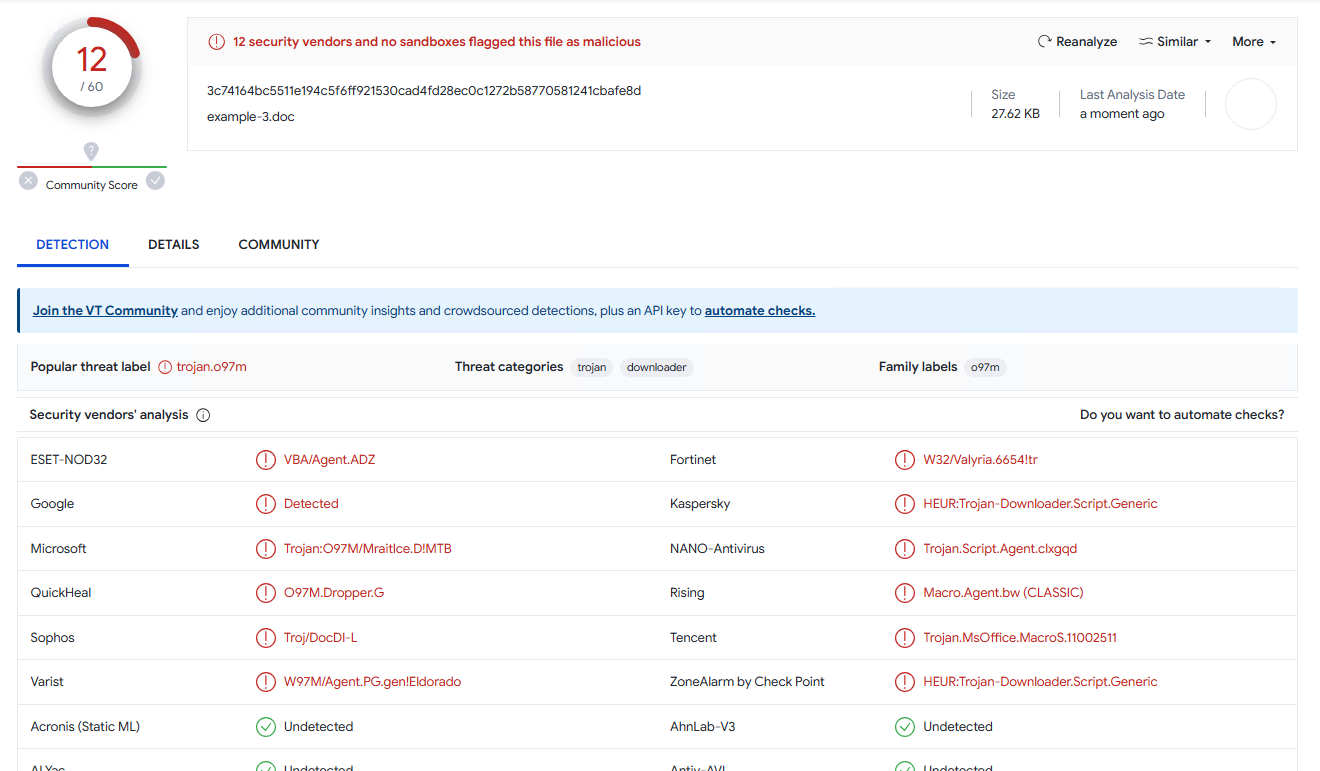
Let’s sprinkle in a little bit of polyglot powers in there. It gets a little bit better (VirusTotal):
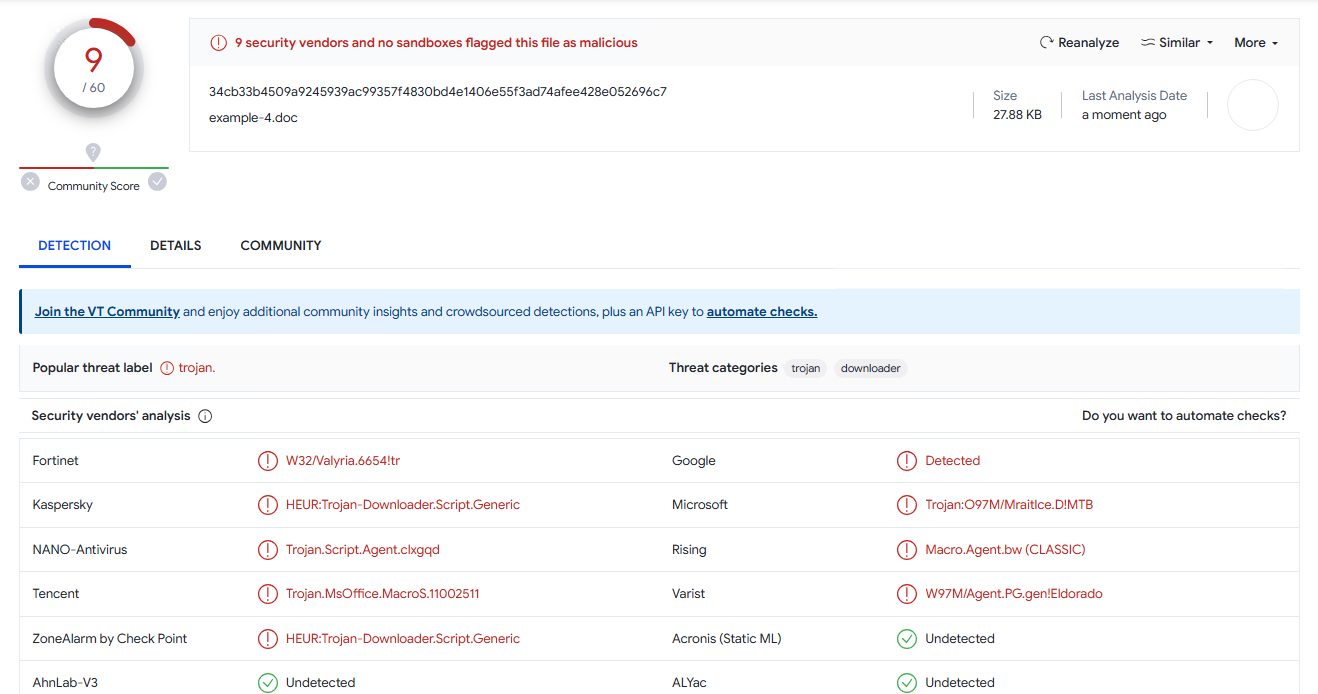
I’ve experimented a little bit to figure out what exactly triggers these AVs and it seems more than likely that it’s just the fact of having these sensitive functions like VirtualAlloc() and the overall technique is so old and well-known, it’d be quite hard to get any better results with this particular runner.
But just to demonstrate the power of this thing on something more life-like (nobody is using this old shit, right?), I wrote just a little bit more complicated runner that uses process hollowing and indirect function calls and in its raw form it’s already not so bad (VirusTotal):
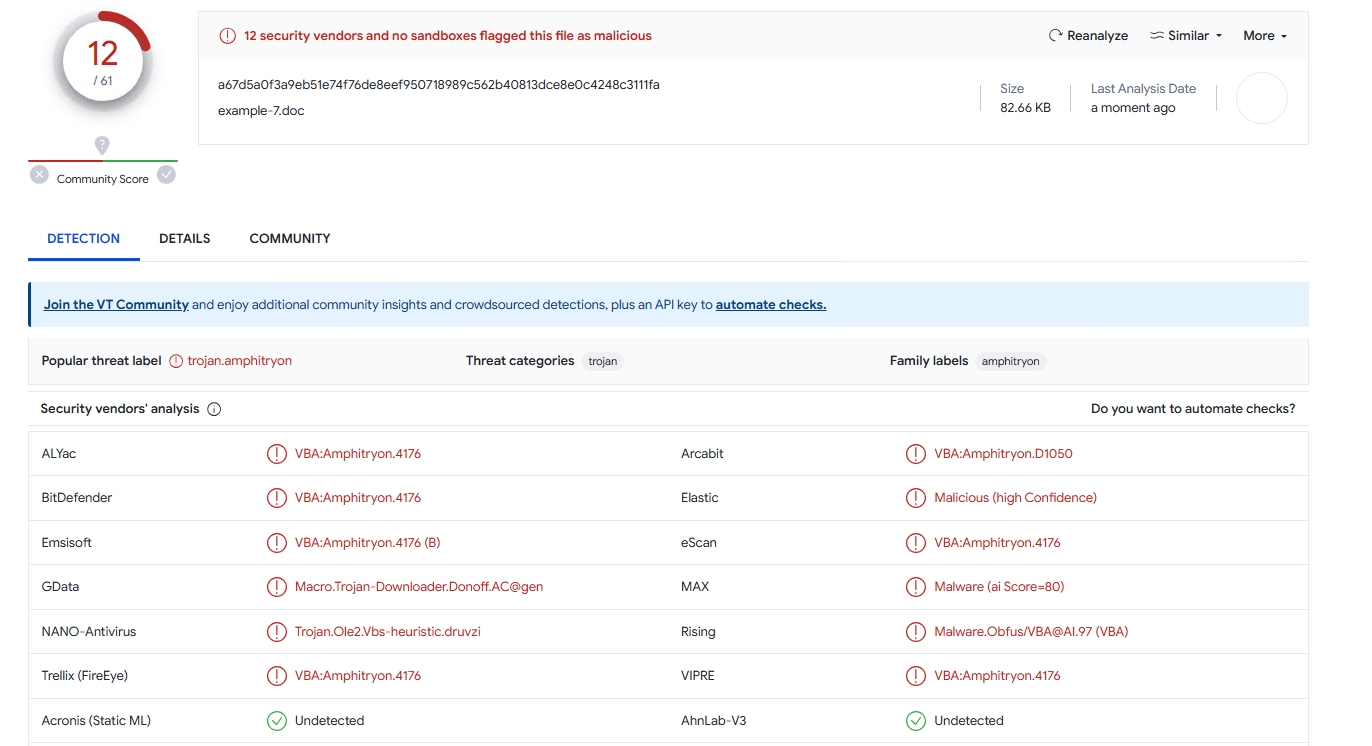
But after applying macro name spoofing and a little bit of polyglot junk, it gets real good (VirusTotal):
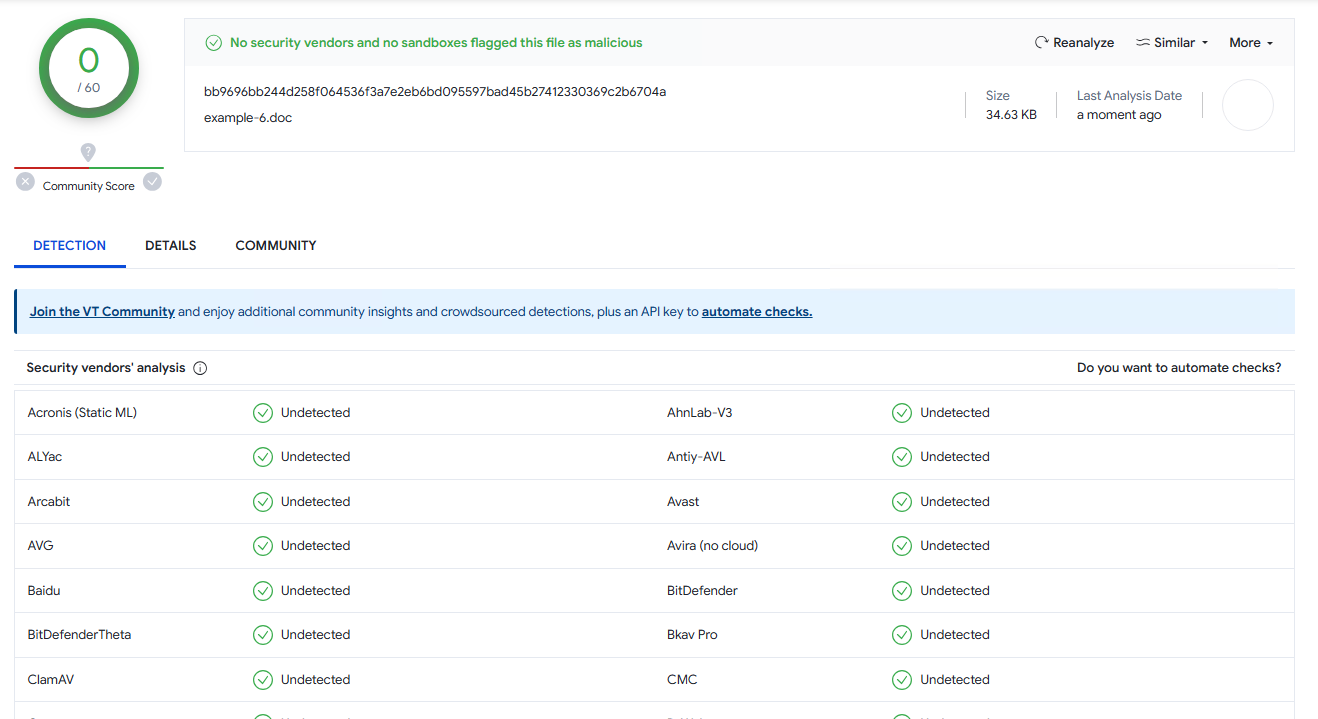
And you can also host the VBA part on a remote, which might help in some scenarios.
ActiveMaim
During the research I wrote several snippets to automate the fuzzing which I ended up combining in a simple tool I called ActiveMaim. It’s basically just a proof of concept generator for some of the techniques I’ve described.
Other formats
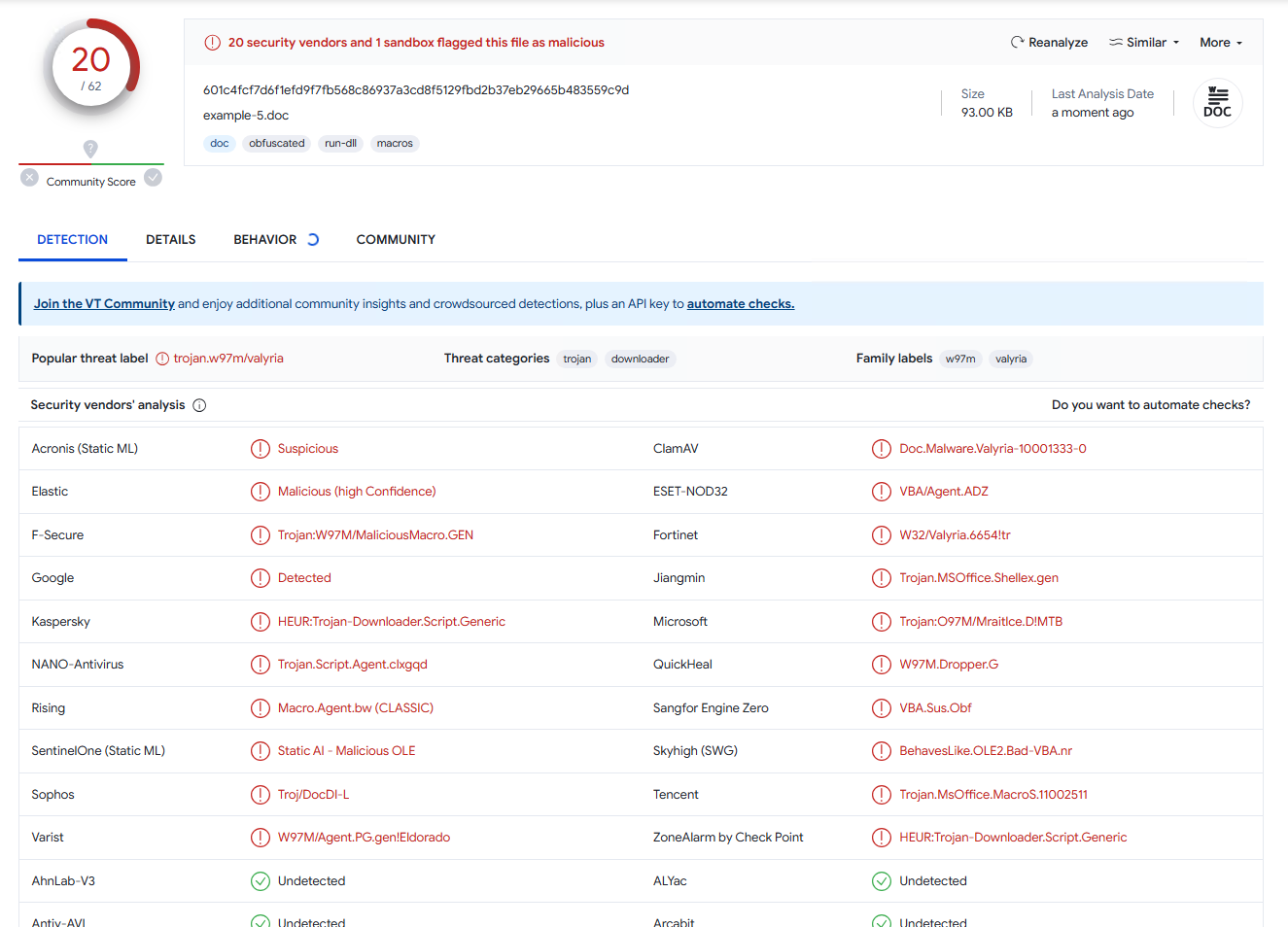
Just for completeness sake, I want to mention that this macro name spoofing technique works in any other format that uses VbaSuppData, but due to more structured and easy to properly parse nature of those formats, it has much less evasion potential. Take a look at the good old Word 97 .doc detection rate for the same payload that got 9 detections in MHTML (VirusTotal):
Conclusion
I feel like there’s a little bit more sensitive functionality hidden in these bytes or at least a little more work to figure out what to change in CFB to make arbitrary length names work, but I started to dream in hex dumps at some point and decided that it’s gonna be enough for me, at least for now.
While the techniques here are rather impactful, I think that in terms of real-life applicability it’s almost useless, at least against mature organizations. It’s not even a vulnerability, more like undocumented functionality or just an implementation quirk at best. I did the responsible thing and discussed this with MS people prior to publication and they agree with me on this.
The main reason for that is the fact that it does not bypass Trust Center policies - Bad Guys will still have to trick the target to enable macros. Even if they do, most of the time macros will be either strictly controlled or disabled by AD policies. And on top of that, of course, the VBA inside Office documents is a dying out thing anyway. It’s still an interesting way of evading detection, though.
In the end, it’s all somewhat trivial: anything improperly documented and complex enough will lead to different interpretations, which is almost always abusable in some way.